

Data Distribution in Power Platform
The below is an extract from our recent white paper, Power Platform in a Modern Data Architecture, which takes on the question of how Power Platform integrates with Azure data services including Microsoft Fabric, outlining five patterns that organizations ought to mix and match to extract Power Platform’s greatest value. This blog post overviews the evolved Data Distribution pattern. Enjoy.
Data Distribution
Point-to-Point, Data Consolidation, Master Data Node, and Data Distribution evolve a similar theme. Specifically, each focuses primarily on transactional data, defined here as data that an application or other workload transacts—creates, reads, updates, or deletes—during any given users interaction with it. Examples are infinite, but let’s consider four quickies:
A safety inspector is completing an inspection of a train in an app hydrated with data such as the type of train, stations, and data concerning the specific inspection itself;
Law firm staff are managing case files in an app hydrated with data such as the case or matter data, parties involved, co-counsel filing deadlines, and a document library;
Doctors, nurses, medical technicians, and administrators are managing patient records in an app hydrated with a specific patients' vital data, medical chart, prescriptions, and test results;
Military personnel managers track basic personnel data, training achievements and requirements, awards, and assignments for the personnel for whom they are responsible… of course, using an app hydrated with this personnel data sourced from multiple databases.
“Data Distribution” is different, focusing less on transactional data and more on data distributed for analytics, enterprise search, integration with third-party or external sources via API, data science workloads, or training or augmenting a large language model (LLM).
To be clear, (a) our previous four patterns support some of these workloads to varying extents, and (b) Data Distribution patterns also facilitate transactional data in a highly scalable way. Let’s make this real by reconsidering each of our transactional data scenarios above, but this time through the lens of Data Distribution:
Train, track, and platform maintenance data is securely shared between the operator of the equipment and the third-party owner(s) of the physical infrastructure—tracks and platforms—upon which the trains operate;
Data pertaining to clients at that same law firm informs an AI-infused workload that combines this with knowledge of upcoming changes to laws and regulations across industries and geographies in order to offer proactive insights to clients and lawyers as to future impacts to a particular clients’ business;
Historical data concerning medical visits, conditions, tests, vaccinations, etc. is used predictively to better calibrate staff ROTAs or the availability of tests and medications;
Military personnel data is used to understand which personnel or units are deployed at, below, or over capacity, and to find the “right person for the job” based on combinations of rank, competencies, and experience.
Notice how we’ve moved from using the data in a transaction performed within the “app” to extracting downstream value from the data itself?
Essentially the most sophisticated and seamless integration of Power Platform to the modern data platform, Data Distribution plugs Power Platform into what in ecosystem-oriented architecture we call a “Data Distribution Neighborhood”, making that data available for a wide range of repurposing and value extraction. Here we are dealing primarily with making data in Power Platform available for value extraction alongside data that might exist in any other technology (e.g., third party data services, Cosmos DB, Azure SQL, etc.) deployed within your cloud ecosystem.
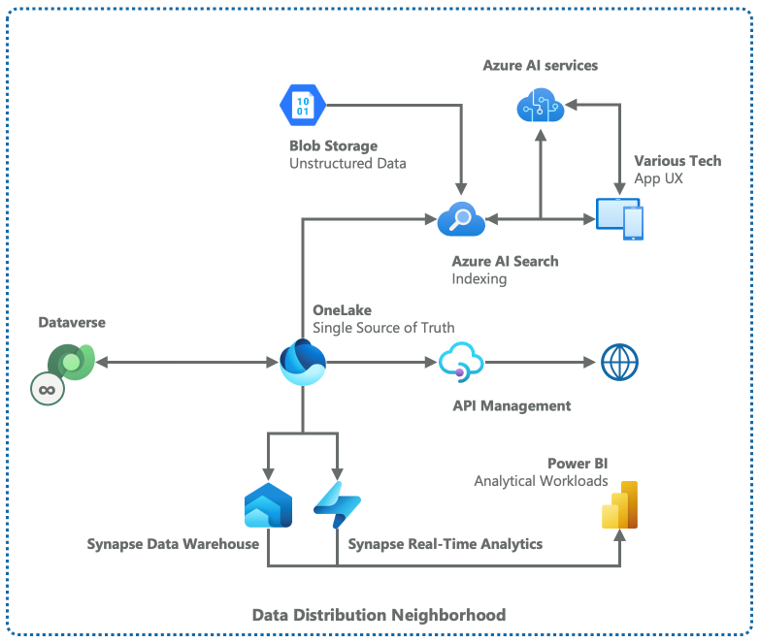
Reference architecture for a typical “data distribution” scenario, where the key objective is to flexibly “distribute” data to downstream uses such as analytics or AI.
This reference architecture shows a representative “Data Distribution Neighborhood” that includes the elements discussed below.
An essentially infinite number of Dataverse environments are represented on the far left. How many and for which purpose is a function of the organization’s needs.
Data from Dataverse is exchanged bi-directionally with OneLake, part of Microsoft’s “Fabric” data platform technologies:
OneLake consumes data from Dataverse via a capability known as a “shortcut”, which is analogous to data as desktop shortcuts are to files in a file system; in other words, data remains in Dataverse but is “shortcutted” (not outright copied) into OneLake, thus preventing copies (and copies of copies) of data from proliferating;
Dataverse consumes data from OneLake via virtual tables the same as virtual tables previously discussed in relation to Azure SQL or SharePoint, where the data resides in OneLake but is made available “virtually” via tables in Dataverse.
The data from OneLake may then be distributed for several scenarios that include (but are by no means limited to):
Indexed by Azure AI Search (alongside unstructured data from Blob Storage) to create a unified search capability across the data estate or with Azure AI services as part of a retrieval-augmented generation (RAG) pattern; these scenarios can then be served back to an end user through various application user experiences (UX), including via embedding in Power Platform solutions or apps;
Secure distribution to third party or external services via API;
Consumption by analytical workloads (dashboards, charts, reports, visualizations, etc.) in Power BI via Synapse services as appropriate, or via direct connection to OneLake itself.
As you can see, integrating Power Platform to a more comprehensive Data Distribution pattern enables multiple downstream scenarios that extract value from the data housed within Power Platform broadly and Dataverse specifically.
I mentioned AI workloads and RAG patterns above, but let’s explore this further in the architecture below.

Functional workloads (red icons) built in Power Platform have been arranged with Dataverse and combined with a RAG pattern to demonstrate how data may be exchanged between Power Platform solutions and AI workloads.
On the right we have a collection of tier 1 or “core business system” workloads built with Power Platform, all atop Dataverse as their application data service. Dataverse then shortcuts that data into OneLake, where it is indexed by Azure AI Search, thereby also making that Power Platform data searchable as part of an enterprise-wide search capability.
Meanwhile, on far left we see an application user experience (UX)—e.g., a mobile, tablet, or web app, built with Power Apps, of course—that provides an end user the ability to interact with our AI workload.
The application sitting beneath the UX queries the knowledge contained in Azure AI Search’s index (as derived from the data sources on the right). It then passes that prompt and knowledge to Azure AI services to generate an appropriate response to be fed back to the user.
The Power Platform components in this architecture are shown glowing in blue, demonstrating the extent of the integration between Power Platform, Fabric, and Azure AI services.
I wrote more extensively on this pattern in the January 2024 white paper Crafting your Future-Ready Enterprise AI Strategy and in my March 2024 piece How Power Platform Scales Generative AI Across an Organization. You can find a crash-course on RAG patterns at RAG and the fundamentals of AI acting on enterprise data.
To summarize, our Data Distribution pattern integrates Power Platform workloads to downstream distribution scenarios such as AI, analytics, and distribution via API. This pattern leverages Power Platform for rapid application development, aggregating data transacted in Power Platform into OneLake for lake and lake house architectures, establishing a truly “single source of truth” for data across the organization. Power Platform accelerates this adoption of a modern data platform by (rapidly) enabling data collection and service delivery to end users.
Data Distribution requires a proper data platform to be built, including capabilities to secure, govern, catalog, manage lineage, and hydrate that data to downstream services. Representative technologies and techniques here include:
OneLake aggregates data from Dataverse environments using shortcuts;
Azure AI Search indexes data in the lake for AI and search workloads;
Azure API Management facilitates distribution of data via API;
Microsoft Fabric beyond just OneLake (including Synapse) feed analytical, data engineering, and data science workloads.
If you’re keen to know more about Point-to-Point, Data Consolidation, Master Data Node and Data Landing Zone patterns, you can find all this covered in the whitepaper, Power Platform in a Modern Data Architecture. Thanks for reading.